
On April 15, ByteDance’s Seed team released a technical paper titled “Seedance 2.0: Advancing Video Generation for World Complexity”, showcasing the core capabilities and evaluation results of this multimodal video generation model.
Seedance 2.0 was launched in early February and is currently integrated with Doubao, Jimeng AI, and Volcano Engine, with the model ID doubao-seedance-2-0-260128. Additionally, ByteDance offers an accelerated version, Seedance 2.0 Fast, aimed at low-latency scenarios.
Compared to its predecessors, Seedance 1.0 and 1.5 Pro, the most significant change in Seedance 2.0 is the shift from “generating short video clips” to “supporting controllable video synthesis with various control signals.” It employs a unified, large-scale multimodal audio-video joint generation architecture, natively supporting four input modalities: text, images, audio, and video. On the open platform, it can accept up to 3 video clips, 9 images, and 3 audio segments as references, directly outputting audio-visual content of 4–15 seconds at 480p or 720p resolution.
From ByteDance’s evaluation results, Seedance 2.0 outperformed models such as Kling 2.6, Kling 3.0, Sora 2 Pro, Veo 3.1, and Seedance 1.5 across all dimensions in three main tasks: Text-to-Video (T2V), Image-to-Video (I2V), and Reference-to-Video (R2V). On the Arena.AI evaluation platform, Seedance 2.0 once topped both the T2V and I2V rankings, though it has since been surpassed by HappyHorse-1.0, now ranking second by a narrow margin.
Notably, this paper focuses on “capability evaluation and product implementation” and does not delve deeply into model architecture and training details.
The evaluation results are primarily based on ByteDance’s self-built evaluation set, SeedVideoBench 2.0. This framework is an upgraded version of SeedVideoBench 1.5, introducing a multimodal task evaluation system covering four major task groups (reference, editing, extension, combination) and a narrative quality evaluation system (including shot language, plot design, and stylistic aesthetics), utilizing both objective and subjective scoring.
1. High-Fidelity Audio-Visual Generation Following Real-World Laws
As a native multimodal audio-video generation model, Seedance 2.0 has made substantial and comprehensive improvements in all key sub-dimensions of video and audio generation, demonstrating performance comparable to industry leaders in expert evaluations and public user tests. The paper outlines four core capabilities of Seedance 2.0:
-
Real-World Complexity Generation. Seedance 2.0 significantly enhances the naturalness, temporal coherence, and physical realism of human motion modeling, capable of generating temporally accurate complex interactive scenes that strictly adhere to real-world motion laws, alleviating common generation artifacts. In close-up shots, details such as light refraction and interactions between characters and environments closely resemble real footage; the usability of multi-entity interactions and complex motion scenes is notably higher than recent commercial models.
-
Strong Multimodal Capabilities. The model accurately parses multimodal inputs, strictly following instructions across dimensions such as composition, shot design, motion rhythm, and acoustic features, and supports direct quoting of text storyboard scripts. Even when faced with complex scripts involving numerous character interactions and detailed action descriptions, it maintains subject identity consistency; it also possesses basic directing and cinematographic reasoning abilities, autonomously planning shot sequences and visual presentation templates. The 2.0 version has added video editing and continuation features, allowing for targeted modifications to specified segments, characters, actions, or plots, or seamless extensions of existing materials.
-
High-Fidelity Audio-Visual Generation. Equipped with an upgraded audio generation module, it integrates binaural audio technology, capable of simultaneously outputting background sounds, environmental sound effects, character voiceovers, and other multi-track content, faithfully reproducing subtle natural environmental sounds and aligning them precisely with visual rhythm, supporting professional-grade audio-visual content creation.
-
Productivity Scene Applications. It demonstrates strong cross-scenario adaptability across various use cases such as commercial advertising, film special effects, game animation, and commentary videos. ByteDance believes that AI-generated content can significantly reduce the production costs and timelines of professional audio-visual content, aiding creators and enterprises in realizing their ideas.
From Seedance 1.5 to Seedance 2.0, the generation framework has shifted from synchronized audio-video generation to unified multimodal audio-video joint generation. The ByteDance Seed team emphasizes that the Seedance series is built around a unified architecture, with the core goal of high-fidelity reconstruction of the complexity of the real world.
2. Text-to-Video: Leading Motion Quality and Improved Physical Modeling
In the Text-to-Video (T2V) task, the ByteDance team systematically compared Seedance 2.0 with five contemporaneous models: Kling 2.6, Kling 3.0, Sora 2 Pro, Veo 3.1, and Seedance 1.5. The evaluation covered six dimensions: motion quality, video instruction adherence, aesthetics, audio quality, audio-visual synchronization, and audio instruction adherence.
Overall, Seedance 2.0 ranked first in all six dimensions, being the only model to score above 3.4 in every dimension (on a 5-point scale), with an average improvement of 0.86 points over Seedance 1.5, the largest enhancement being in motion quality, which improved by 1.36 points. Both motion quality and audio-visual synchronization scored 3.75, leading the second-place model by at least 0.65 points.
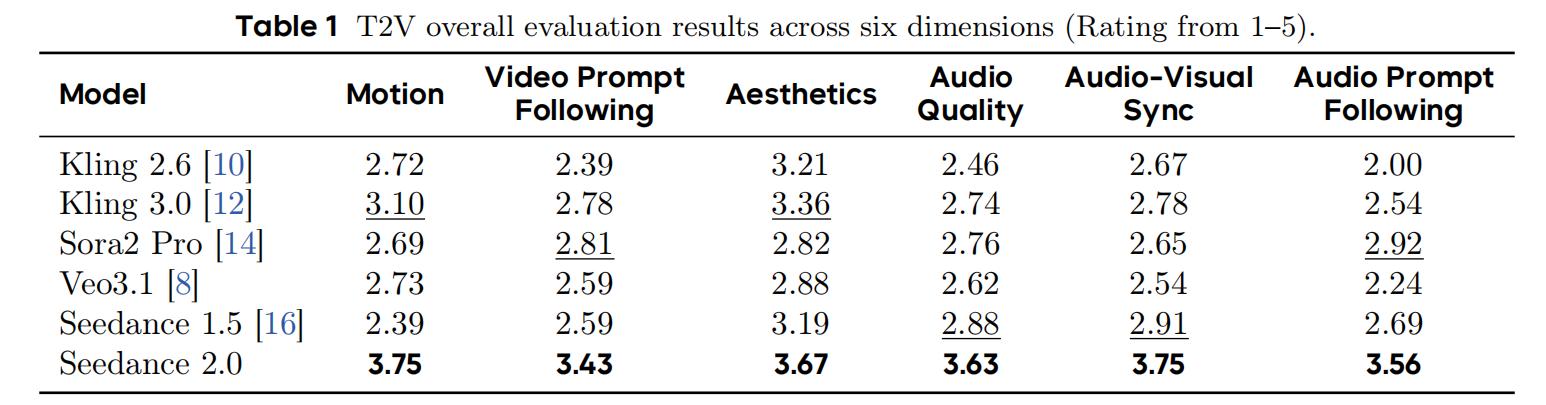
Motion quality is the area where Seedance 2.0 shows the most significant improvement compared to version 1.5. In 30 subcategories, Seedance 2.0 ranked first in 29 of them (only tying with Kling 3.0 in group coordination), with scores ranging from 3.29 to 4.43. Notably, features such as multi-entity matching (4.43), composition (4.25), and editing rhythm (4.21) all exceeded 4.0.
Moreover, Seedance 2.0 shows significant improvements in physical modeling: where Seedance 1.5 previously scored low in dimensions such as physical feedback (1.69), natural phenomena (2.00), and intense motion (2.00), the 2.0 version improved by over 1.5 points in each.
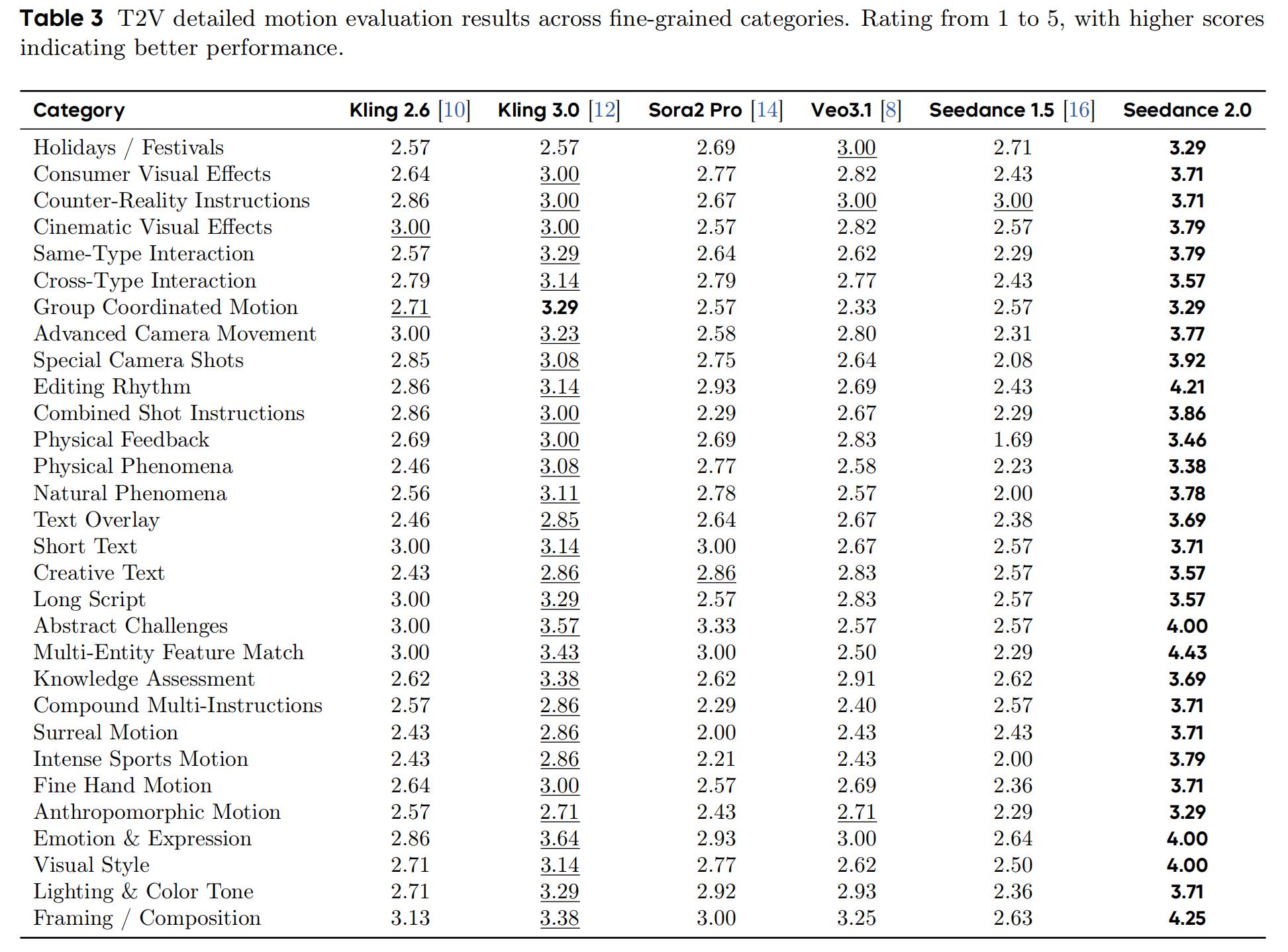
Aesthetics is the dimension with the smallest gap among competitors. Seedance 2.0 ranked first in 28 out of 30 subcategories (including ties), with overall scores ranging from 2.79 to 4.14. The highest scoring dimensions were visual style (4.14), long scripts (4.14), and composition (4.13).
In comparison, Kling 3.0 scored above 3.5 in 13 aesthetic categories, with its strongest areas being surreal motion (3.86), similar-type interactions (3.79), and composition (3.75); Sora 2 Pro and Veo 3.1 were notably weaker in holiday and consumer effects categories (both dropping below 2.5).
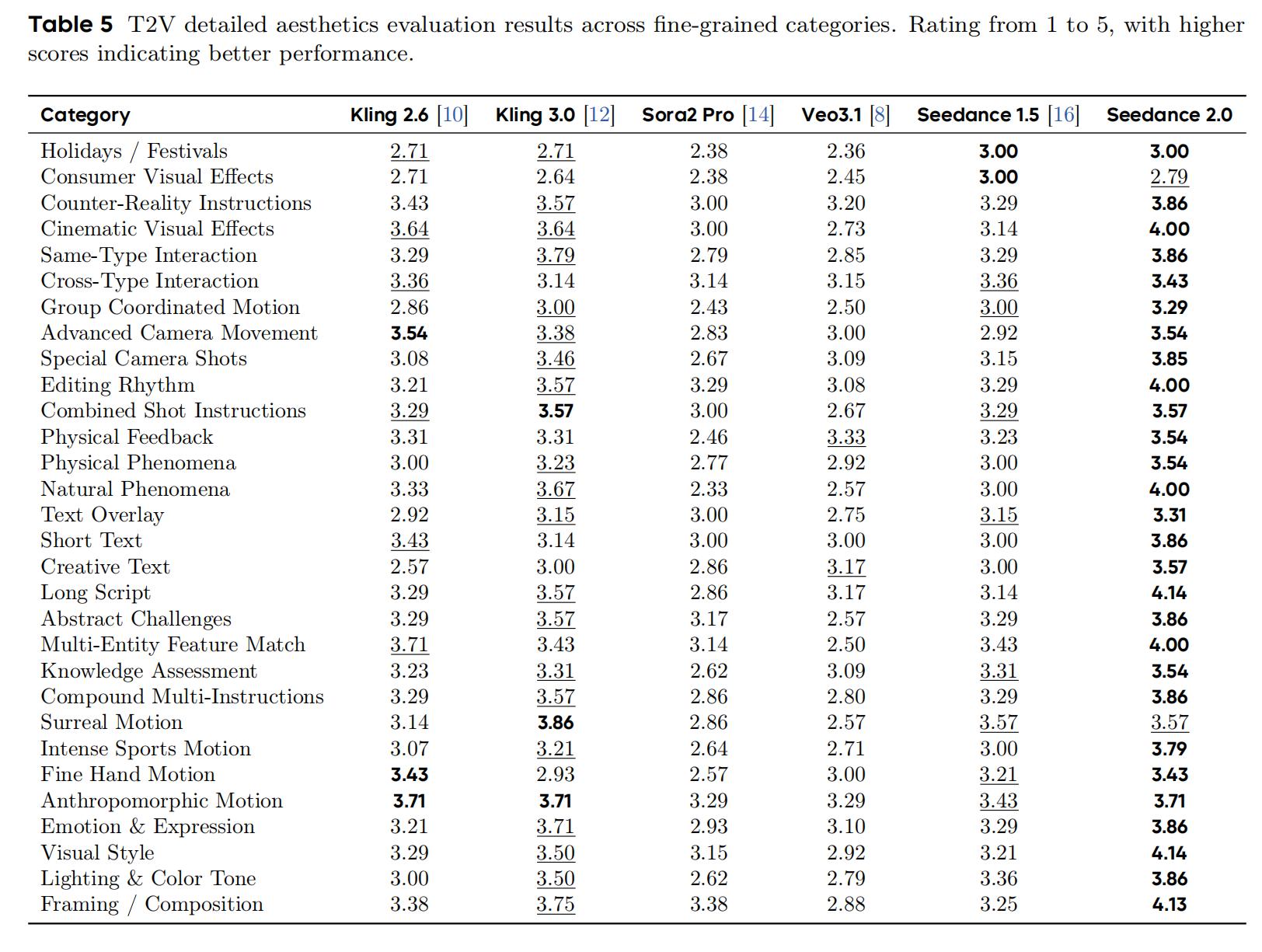
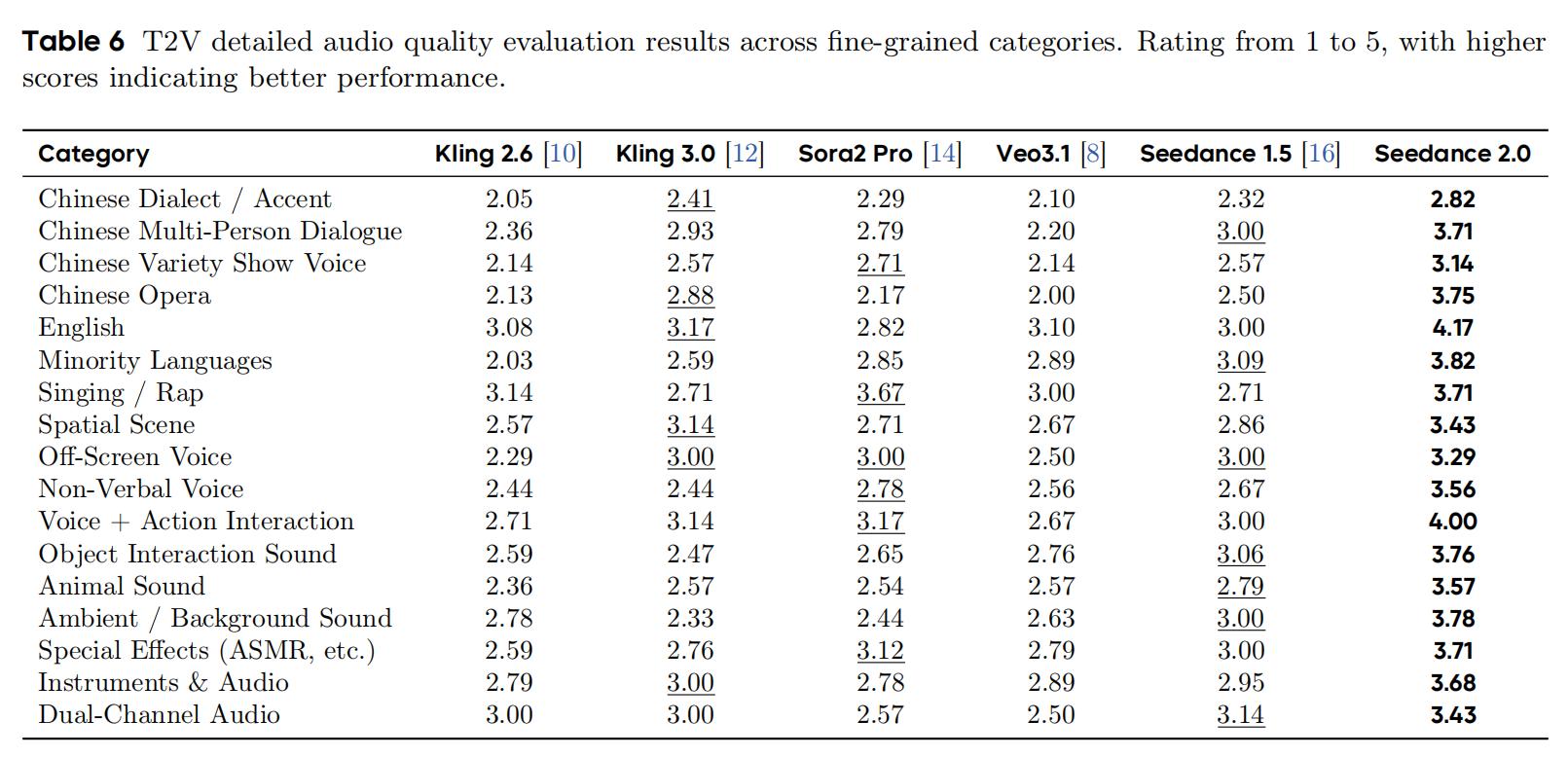
Audio quality is another advantage of Seedance 2.0. It ranked first in all 17 subcategories, with scores ranging from 2.82 to 4.17. Strong points include English (4.17), voice + action interaction (4.00), minority languages (3.82), and environmental/background sounds (3.78).
Compared to Seedance 1.5, the most significant improvements were in Chinese opera (2.50→3.75), English (3.00→4.17), and singing/rap (2.71→3.71).
From the competitor’s perspective, aside from Sora 2 Pro’s singing/rap (3.67), no other competitors scored above 3.2 in any single category. Kling 3.0 showed regression in singing/rap and environmental/background sounds compared to its predecessor, Kling 2.6. Overall, competitors generally exhibit issues with murky audio, significant noise, and weak layering, particularly in complex sound effects and clarity of human voices.
3. Image-to-Video: Significant Audio Lead, Competitive Image Retention
In the Image-to-Video (I2V) task, ByteDance compared Seedance 2.0 with Wan 2.6, Kling 2.6, Veo 3.1, Kling 3.0, and Seedance 1.5 Pro, evaluating six dimensions: motion quality on the video side, video instruction adherence, image retention, and audio quality, audio-visual synchronization, and audio instruction adherence on the audio side.
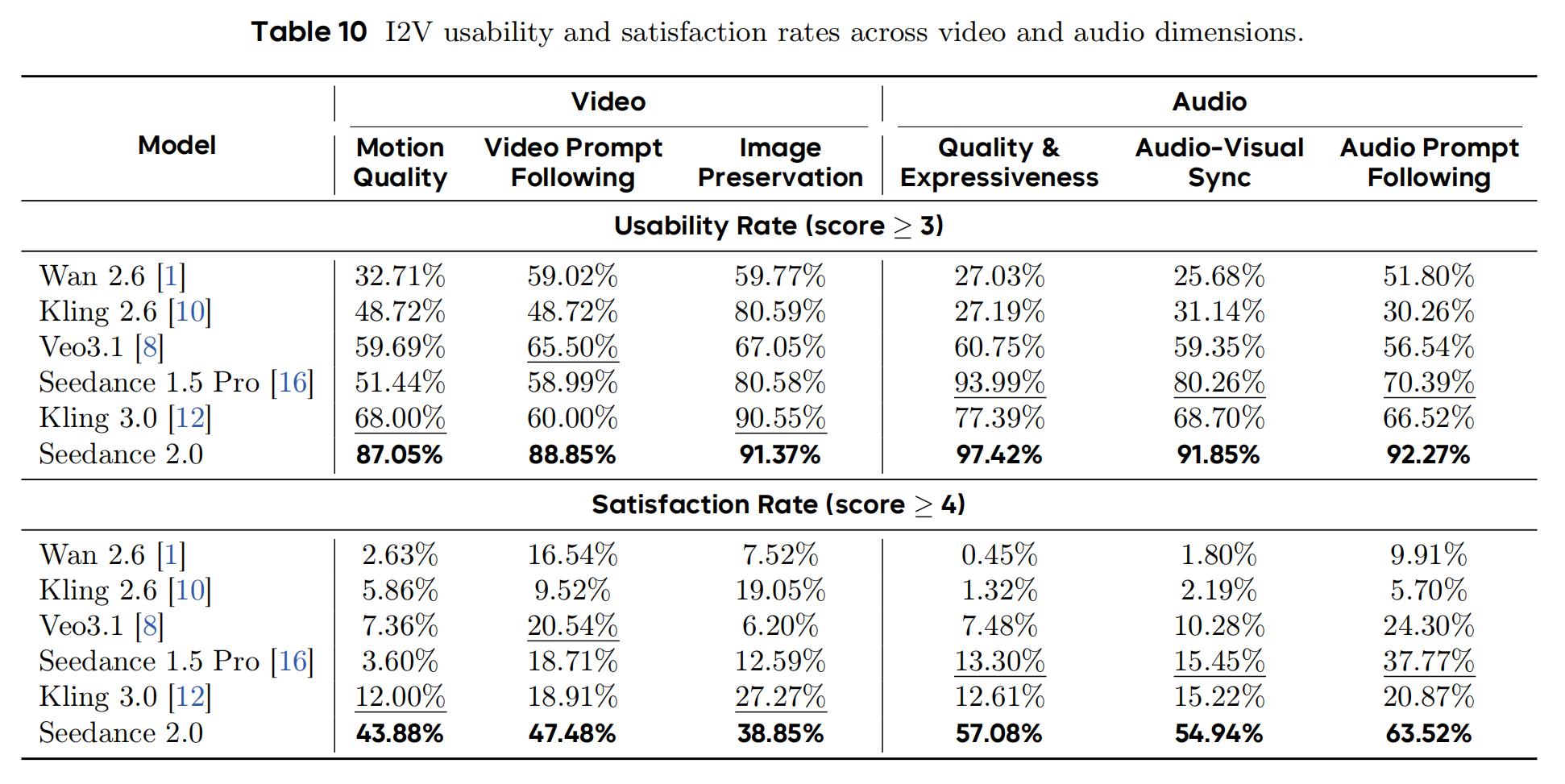
Seedance 2.0 ranked first in all six dimensions, with scores ranging from 3.31 to 3.70, and no competitors exceeding 3.18. Among these, image retention saw fierce competition, with Kling 3.0 trailing by only 0.13 points, while motion quality had a 0.55 point lead. Audio remained a collective shortcoming among competitors, with Kling 2.6 (2.21) and Wan 2.6 (2.18–2.55) all scoring below 3.0, while the second-place Seedance 1.5 Pro lagged by 0.54–0.60 points.
Seedance 2.0 is the only model with a usability rate exceeding 87% across all six dimensions: motion quality satisfaction rate at 43.88%, over three times that of the second-place Kling 3.0 (12.00%); video instruction adherence satisfaction rate at 47.48% vs. Veo 3.1’s 20.54%. The audio gap is even more pronounced—audio quality satisfaction rate at 57.08%, while Kling 2.6 and Wan 2.6’s usability rates were below 28%, indicating that most competitors’ audio outputs are directly unusable; audio instruction adherence satisfaction rate at 63.52%, which is 1.7 times that of Seedance 1.5 Pro (37.77%) and over 10 times that of Kling 2.6 (5.70%).
In addition to scoring, the ByteDance team observed that Seedance 2.0 can mix slow-motion highlights with fast actions in scenes like fighting and dancing, with more vivid character expressions and eye movements; it features varied camera movements, introducing first/third-person game perspectives and handheld breathing effects; it maintains visual coherence across special styles like felt, oil painting, and fine brushwork; and it accurately conveys emotional layers in bilingual dialogues, including Sichuan, Northeast, and Cantonese dialects, with natural coordination of voice, sound effects, and background sounds.
4. Reference-to-Video: Strong Overall Strength with Wide Multimodal Task Support
In the Reference-to-Video (R2V) task, ByteDance compared Seedance 2.0 with Vidu Q2 Pro, Kling O1, and Kling 3.0, evaluating five dimensions: multimodal task adherence, editing consistency, reference alignment, motion quality, and prompt adherence.
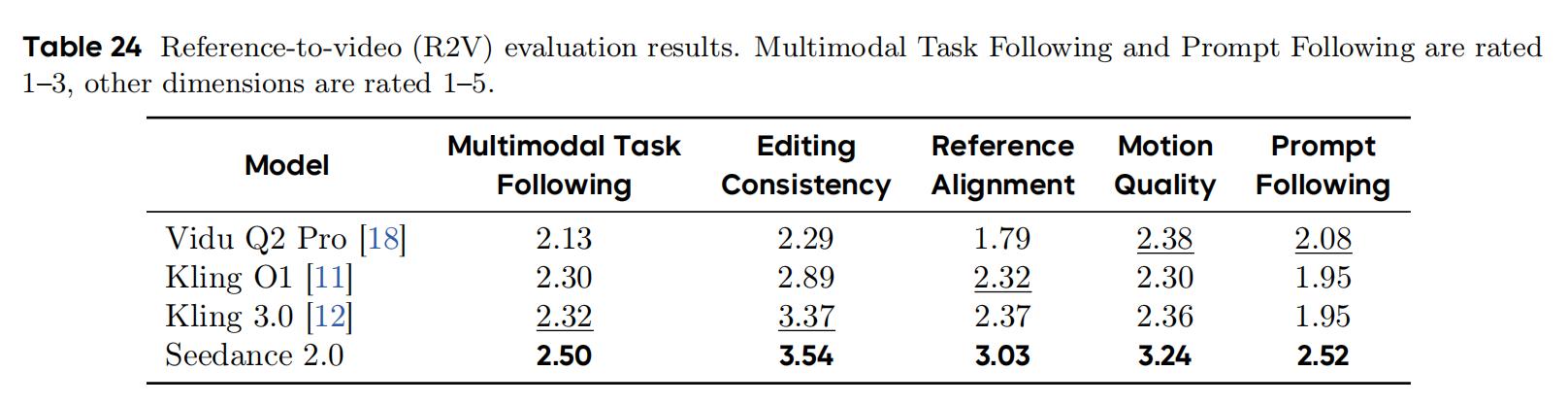
Seedance 2.0 ranked first in all five dimensions: multimodal task adherence 2.50, prompt adherence 2.52 (both on a 1–3 point scale), editing consistency 3.54, reference alignment 3.03, and motion quality 3.24 (on a 1–5 point scale). The largest gap was in motion quality (leading competitors by 0.86–0.94 points) and reference alignment (leading by 0.66–1.24 points), while the smallest was in editing consistency (Kling 3.0 lagged by only 0.17 points).
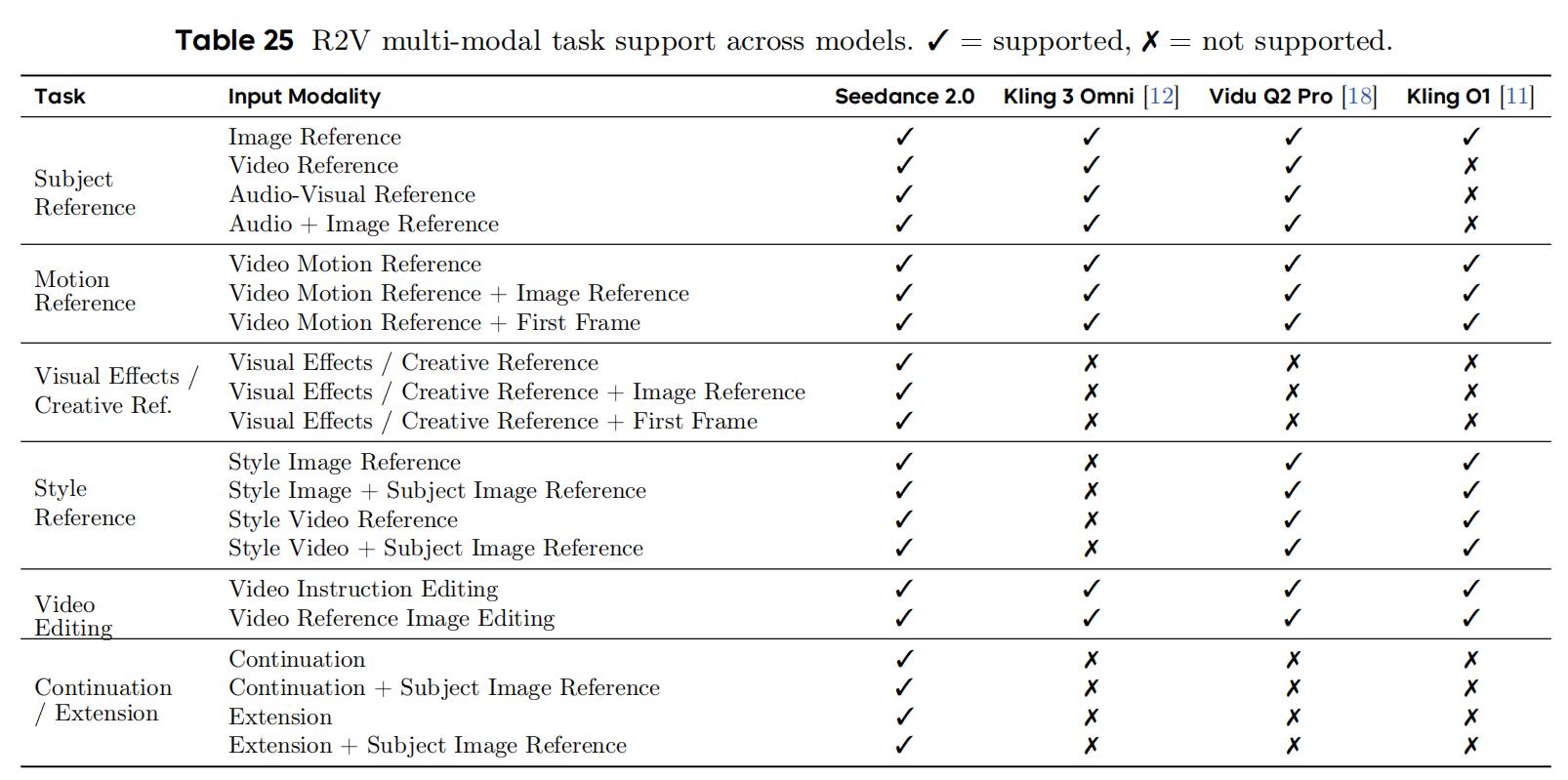
Notably, the breadth of multimodal task support is significant. Seedance 2.0 supports 20 out of 22 input modal tasks, the widest coverage in the evaluation; in contrast, Kling 3 Omni supports 9, Vidu Q2 Pro supports 13, and Kling O1 supports only 10. Among these, visual effects/creative references (3 variants) and continuation/extension (4 variants) are tasks that only Seedance 2.0 can handle, representing its most notable differential advantage in R2V tasks.
However, Seedance 2.0 is not without its shortcomings. In the video extension task, Veo 3.1 leads with a task adherence score of 2.78 (88.89% 3-point rate), significantly ahead of Seedance 2.0’s 1.93 (31.82%). Reference alignment is also higher for Veo 3.1 at 3.44 compared to 3.28 for Seedance 2.0, with the paper stating this is Seedance 2.0’s weakest single item in R2V. ByteDance explains that Seedance 2.0 can accept any uploaded video for extension, while Veo 3.1 can only extend videos it generates, meaning the broader input range comes at the cost of quality stability.
5. Conclusion: More Refined Video Generation Aligned with Real-World Physics
From the paper, Seedance 2.0 demonstrates considerable overall strength in both video and audio generation, reflecting ByteDance’s long-term accumulation in generative media technology.
However, it is important to note that this paper has a temporal boundary; the evaluation data cited is up to early April 2026 and does not include new competitors that have emerged since then, such as the recently top-ranking HappyHorse-1.0. The ByteDance team also acknowledges that Seedance 2.0 still has minor issues such as slight deformation artifacts, edge scene motion rationality, high-frequency visual noise, audio distortion, and multi-character lip-sync errors.
In a broader perspective, the video generation field is increasingly demanding for both new and old players, with rising expectations for precise control, audio-visual synchronization, and alignment with real-world physics. The speed at which new models are introduced is undoubtedly faster than the pace of paper publication.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.