Introduction
AI is transitioning from language models to a new era of world models, fundamentally changing the nature of intelligence. This article delves into how world models empower AI with foresight, causal reasoning, and spatial intelligence, revealing a paradigm shift from passive reactions to proactive planning.

The Evolution of AI
AI has undergone several transformative phases:
-
Symbolism (Logic-Centric): Defined logical relationships with clear rules.
- Flaw: Applicable only to linear patterns; extreme cases are hard to explain.
- Example: Both cats and mice have fur, ears, and four legs.
-
Connectionism (Data-Centric): Used data and probabilities for machines to fit results.
- Flaw: Forcing unrelated data connections to fit.
- Example: Ice cream sales and drowning rates are correlated due to summer activities.
-
Relationalism (Association-Centric): Machines understand semantic associations of words.
- Flaw: Machines can make nonsensical assertions based on strong correlations.
- Example: Asking a machine what Lin Daiyu pulls up results in “willow branches.”
-
Causalism (Physics-Centric): The world is continuous while language is discrete.
- Machines simulate the real world to predict the future.
- Flaw: Computers have limited calculations; real-world continuity is complex.
- Example: A ruler measures not just 10cm but an exact, unrepresentable number.
Understanding the World Model
In the grand narrative of AI, we are at a pivotal turning point. While attention is focused on how large language models (LLMs) generate text, code, and images, a deeper, more disruptive concept is quietly reshaping the future of AI—World Models.
So, what exactly is a world model?
Essentially, a world model is a small, operational simulator constructed internally by AI systems to understand and predict the dynamic changes in their environment. It encapsulates core principles about how the world operates, including physical laws, interactions between objects, spatiotemporal relationships, and causal logic. Through this internal model, AI is no longer just passively responding to external stimuli but can actively conduct “thought experiments”—simulating various scenarios in its “mind” before taking action, thus making better decisions.
As technology evolves, the concept of “world models” has become richer, typically referring to three interrelated but distinct concepts:
- Learned Internal World Models: The classic definition, referring to a dynamic model learned by the agent for prediction and planning. For instance, DeepMind’s Dreamer models exemplify this concept by “imagining” future trajectories in learned latent spaces to develop behavior strategies.
- External Simulators: Manually created environments by human developers for training and evaluating AI, such as physics engines (MuJoCo, NVIDIA Omniverse) or driving simulators (CARLA). These environments are also a type of “world model,” but their rules are predefined rather than learned by AI.
- World Foundation Models: The newest and grandest concept, referring to ultra-large models pre-trained on vast, diverse datasets (like internet videos) that can generate and simulate open-ended, general worlds. They aim to be a universal “world simulator” akin to large language models in the language domain. OpenAI’s Sora and Google DeepMind’s Genie series are early explorations in this direction.
To understand world models more profoundly, we can distinguish between physical world models and psychological world models. Physical world models emphasize precise simulations of objective laws in the external world (like physical laws and causal relationships), while psychological world models focus on simulating the internal states, intentions, beliefs, and preferences of agents (including other agents). A mature AGI system will likely require the capability to integrate both types of models, understanding how the world operates and why the “actors” within it act as they do.
The Need for World Models
Between 2023 and 2025, large language models (LLMs) represented by the GPT and Claude series swept the globe at an unprecedented pace, showcasing powerful capabilities in language understanding, content generation, and knowledge questioning. However, as applications deepened, the fundamental limitations of LLMs became increasingly apparent. These limitations not only restrict AI’s performance on more complex tasks but also clearly indicate why we need a new paradigm—world models.
The Inherent Ceiling of Large Language Models
The success of LLMs is built on the simple yet powerful training objective of “predicting the next token.” Through self-supervised learning on vast text data, they have learned the statistical patterns of language. However, this paradigm also brings about an insurmountable structural bottleneck, summarized as “knowing the text but not the world.”
- Lack of Physical Common Sense and Causal Understanding: The worldview of LLMs is based on text symbols. They can fluently recite Newton’s laws but do not truly “understand” what gravity means. They know that “fire” and “heat” frequently occur together based on co-occurrence probabilities rather than causal cognition of the combustion process.
- Deep-Seated Hallucination Issues: The “hallucinations” of LLMs—confidently fabricating facts—are one of their most criticized problems. They essentially match high-dimensional patterns probabilistically.
- Static Knowledge and Inability to Learn in Real-Time: The knowledge of LLMs is “frozen” at the cutoff of their training data. They cannot update their knowledge base and worldview in real-time through continuous interaction with the world like humans.
Core Abilities Unlocked by World Models
To break through these “ceilings” of LLMs, world models have emerged. They are not meant to replace LLMs but rather provide a more fundamental foundation that can work in synergy with LLMs. World models unlock a series of critical capabilities that the current AI paradigm lacks by constructing an internal dynamic simulator.
- Planning and Foresight: From passive reaction to active imagination. The core value of world models lies in granting AI “imagination.” By simulating “what if I do this, how will the world change?” agents can explore thousands or even millions of possible futures, assess the long-term value of different action sequences, and formulate optimal strategies.
- Enhanced Sample Efficiency: World models significantly reduce learning costs by creating a virtual environment where agents can “dream.” Agents can conduct massive training in this internal simulation, rapidly mastering skills before transferring learned strategies to the real world. This dramatically improves AI’s learning efficiency, serving as a key engine for the development of embodied AI.
- Safety and Robustness: The real world is filled with rare yet critical scenarios, such as pedestrians suddenly appearing in autonomous driving or extreme weather. Exhaustively capturing these scenarios through real-world data is nearly impossible. World models, especially controllable generative world models, can generate these dangerous or rare scenarios on demand, allowing AI to rehearse repeatedly in a safe virtual environment, significantly enhancing its robustness and safety in the real world.
- Causal and Counterfactual Reasoning: Moving towards true understanding. World models enable AI to perform counterfactual reasoning, answering questions like “what would have happened if…?” For example, an autonomous driving world model can simulate “what would happen if I hadn’t braked?” This ability is foundational for causal understanding, marking a leap for AI from merely discovering “correlations” in data to understanding the underlying “causality”. Only by grasping causality can AI’s decisions be genuinely reliable and interpretable.
- Connecting Language and Reality: Providing “bodies” and “worlds” for LLMs. In future AGI architectures, LLMs and world models will play complementary roles. An embodied agent receiving the instruction “go to the kitchen and get the cup” will have the LLM parse the semantic meaning of the instruction, while the world model will plan the specific navigation path, predict the grasping action, and simulate its physical consequences.
Principles and Significance of World Models
To deeply understand why world models are seen as the next revolutionary frontier in AI, we must analyze their core working principles and explore how these principles collectively construct a new intelligent paradigm. The construction of world models is not a single technology but a fusion of various advanced AI concepts and architectures, centered on learning a compressed, predictable representation of environmental dynamics.
Core Technical Principles of World Models: Perception Encoding, Dynamic Prediction, and Policy Control
1. Perception Encoding: Compressing from Pixels to Concepts
The real world is high-dimensional, complex, and filled with redundant information. Learning and planning directly at the raw pixel level is extremely inefficient. Therefore, the first step of world models is to use an encoder to compress high-dimensional sensory inputs (like camera images) into a low-dimensional, information-dense latent state representation, typically denoted as z. This process is akin to how the human brain distills complex visual signals into core concepts like “there’s a cup on the table.”
Variational Autoencoders (VAEs) are the key technology for achieving this goal. Through this method, VAEs not only learn to compress data but also create a well-structured latent space suitable for generation and interpolation. This latent vector z represents the world model’s abstract understanding of the “now” moment.
2. Dynamic Prediction: Inferring the Future in Latent Space
With the abstract representation z of the current world, the next step of the world model, and its core, is to learn the dynamic change laws of the world. This task is accomplished by a Recurrent Neural Network (RNN), also known as the “memory model” (M). The advantage of RNNs lies in their ability to record time-series information in their internal states.
By training on a large number of real environment interaction sequences, the memory model M learns the “physics engine” or “transition function” of the environment. It knows how the world will evolve when a specific action is taken in a particular state.
Once trained, we can “turn off” the real environment, allowing the agent to perform inference and learning entirely in the latent space generated by the M model.
3. Policy Control: Learning Actions in the “Dream”
With a brain capable of simulating the world, the final step is to enable the agent to learn how to act. This is accomplished by a controller (C), a relatively small neural network that takes the comprehensive representation of the current world state provided by the world model (typically z_t and h_t) as input and outputs the action a_t that the agent should take.
The training process of the controller is revolutionary: it can operate entirely within the “dream” created by the world model. The specific process is as follows:
- Starting from an initial state, the controller proposes an action a based on the current latent state (z, h).
- The memory model M predicts the next latent state z’, reward r, and new hidden state h’ based on (z, h, a).
- This process loops, generating a trajectory entirely produced in “imagination.”
- Using reinforcement learning algorithms (like evolutionary strategies, PPO, etc.), the controller’s parameters are optimized based on the accumulated rewards from the imagined trajectory, enabling it to learn to select action sequences that yield higher returns.
Due to the small size and simple structure of the controller model, and the computational efficiency of the training environment being an internal simulation, the entire learning process becomes exceptionally rapid. In the “World Models” paper, agents achieved performance surpassing all leading reinforcement learning algorithms after just a few hours of “dream training” in a racing game.
The Profound Significance of World Models: A Paradigm Revolution from Simulation to Understanding
The principles of world models not only bring technological breakthroughs but also signify a profound shift in the philosophy and developmental path of artificial intelligence.
- The Essence of Intelligence is Prediction: The core idea of world models aligns with the theory of “predictive coding” in cognitive science. It shifts AI’s core task from “recognition” and “classification” to “prediction,” which many researchers consider a necessary path to true intelligence, as Yann LeCun stated: “Prediction is the essence of intelligence.”
- The Leap from Data-Driven to Model-Driven: Traditional deep learning, including LLMs, is largely data-driven. Their capabilities directly stem from statistical patterns in vast datasets. In contrast, model-based reinforcement learning (Model-Based RL) based on world models opens up a model-driven paradigm.
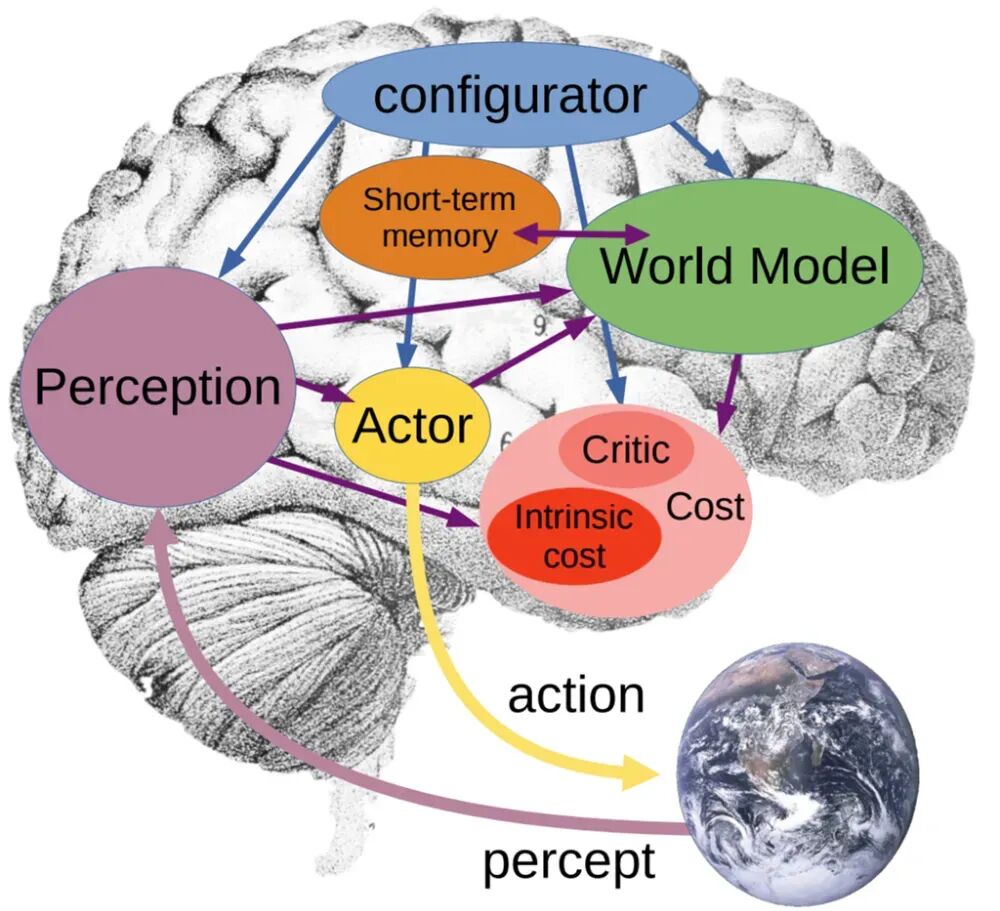
- Paving the Way for Embodied Intelligence and AGI: World models are an indispensable part of achieving embodied AI. A robot that needs to act in the physical world must possess the ability to predict the consequences of its actions to ensure safety and efficiency. World models provide this intrinsic “physical intuition.” Furthermore, a complete AGI system needs to integrate various capabilities such as perception, memory, reasoning, planning, and action. In Yann LeCun’s proposed autonomous machine intelligence architecture, world models occupy a core position, linking perception, memory, cost, and action modules, serving as the hub for advanced cognitive activities within the entire system.
This transformation enables AI to evolve from a mere “observer” that can describe the world to a potential “participant” capable of transforming it, marking a paradigm revolution in the history of AI development.
A New Era for AI
Spatial Intelligence: The Next Frontier for AI
This concept has been emphasized by leading figures in the AI field, such as Stanford professor Fei-Fei Li and her World Labs initiative. In her November 2025 declaration, “From Language to the World: Spatial Intelligence is the Next Frontier for AI,” she systematically elaborated on this idea.
She believes that the cornerstone of human intelligence is not language but the ability to interact with the physical world. Infants build a preliminary understanding of the world through perception and action before learning to speak. Whether parking, catching keys, or navigating a firefighter through a burning building, these abilities rely on our intuitive understanding of space, objects, and dynamic relationships—an ability that LLMs lack.
Thus, the evolution of AI must transcend one-dimensional text sequences and enter a three-dimensional, four-dimensional (plus time) world. Building AI with spatial intelligence requires world models. A true world model should possess three core capabilities:
- Generative: Able to generate a world consistent in perception, geometry, and physics.
- Multimodal: Capable of processing various forms of input and output, including images, videos, text, depth maps, and actions.
- Interactive: Able to generate the next state of the world based on input actions, achieving closed-loop interaction with the environment.
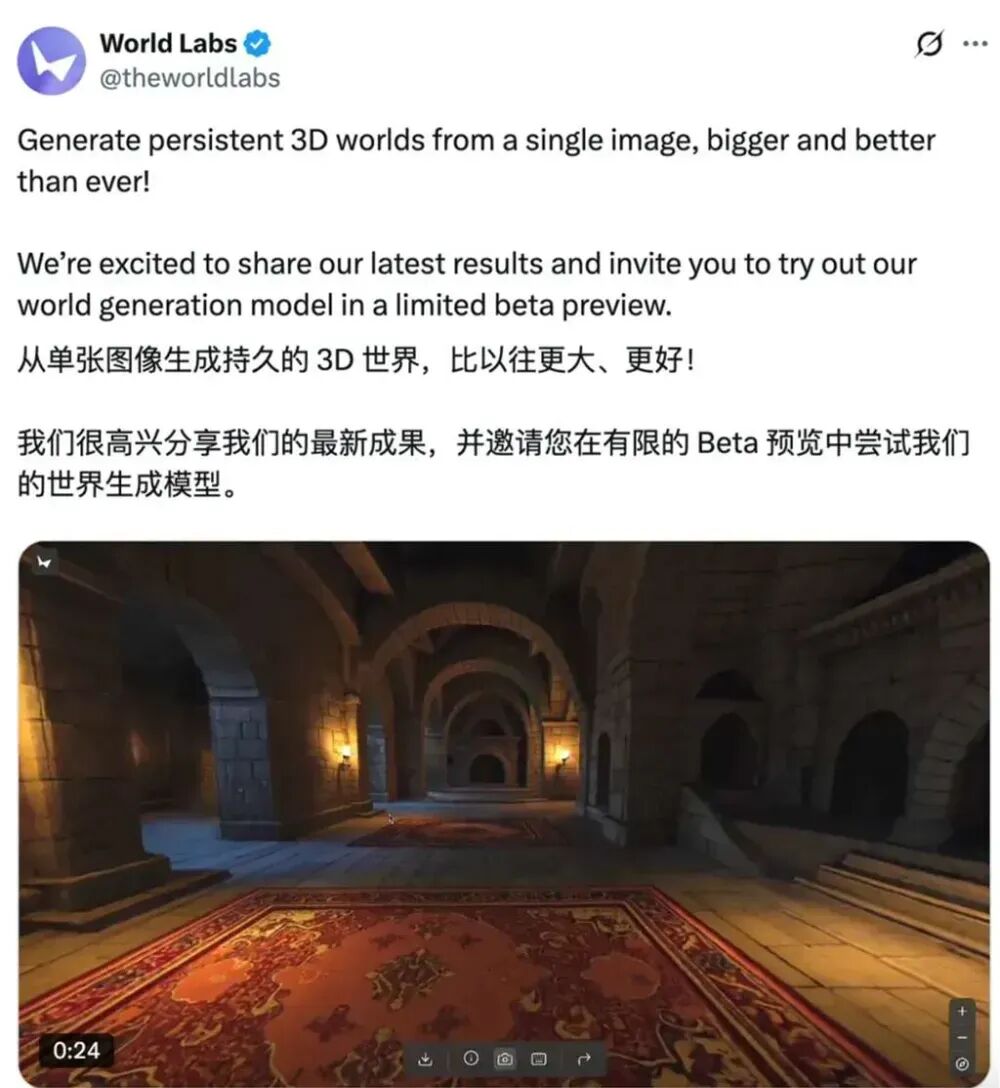
In November 2025, Fei-Fei Li’s World Labs released an early version of its world model product, Marble. Marble can generate persistent, downloadable 3D environments from text, images, or videos, and supports compatibility with mainstream engines like Unreal and Unity, even providing VR support. This marks the transition of world models from research to commercial products, offering new productivity tools for robotics, autonomous driving, industrial design, and entertainment.
Embodied Intelligence: The Carrier of AI from Virtual to Reality
If world models are the “brain” of AI, then embodied intelligence is its “body.” Only by interacting with the real world through physical entities can AI achieve true understanding and intelligence. By 2025, embodied intelligence became the focal point of the global AI competition, especially in China, where it was elevated to a national strategy, viewed as key to integrating AI from the digital economy into the real economy.
The development logic of embodied intelligence is closely tied to world models. For a robot to complete a simple task like “pouring a glass of water,” it needs to:
- Perceive: Identify the positions and shapes of the cup, kettle, and table through cameras.
- World Modeling: Construct an internal dynamic model of the scene, understanding the rigidity of objects, the fluid properties of water, and gravity.
- Planning: Based on the model’s predictions, plan a safe trajectory for grasping, moving, and pouring.
- Action: Control the robotic arm to execute the planned actions precisely.
- Feedback: Adjust actions in real-time using force sensors and visual feedback to respond to unexpected situations (like a sliding cup).
This “perception-modeling-planning-action-feedback” closed loop is a manifestation of world models in the physical world. Without a reliable internal world model, a robot’s behavior would be blind and fragile. Research reports from China’s Ministry of Industry and Information Technology clearly indicate that introducing world models based on visual-language-action (VLA) models is a key path to enhancing the capabilities of large models in robotics.
In 2025, we witnessed vigorous development in this field. Tesla’s FSD V13/V14 versions further deepened its end-to-end AI architecture, which Musk described as a driving system driven by world models. Huawei’s Pangu model 5.5 includes world model capabilities in its multimodal abilities, enabling the construction of digital physical spaces for intelligent driving and robot training. Companies like Yushun and UBTECH in China have also begun integrating stronger environmental perception and autonomous decision-making capabilities into humanoid robots. These advancements indicate that AI is accelerating its “embodiment,” transforming from a “thinker” in a virtual world to a “doer” capable of acting in the physical world.
The new era of AI is one of “knowing and doing”. World models provide the depth of “knowing,” while embodied intelligence offers the means of “doing.” The combination of the two is taking artificial intelligence to unprecedented heights, enabling it to genuinely share and transform the physical world.
Research Directions of Global Giants on World Models
As world models become a strategic high ground in the AI field, top global tech giants and research institutions are investing heavily, embarking on a fierce competition concerning the future along their respective philosophical and technical paths. By early 2026, we can clearly see several parallel yet interwoven mainstream research directions shaping the landscape of world models.
Generative Path: Centered on Simulating the World
The core idea of this path is to train large-scale generative models on massive video data, allowing the models to “brutally” learn the physical laws and dynamic characteristics of the world, thus becoming a universal, interactive world simulator. This can be seen as a form of “algorithmic empiricism,” believing that knowledge arises from the induction of sensory data.
Google DeepMind: From Genie to SIMA, Building Interactive Training Grounds for Intelligent Agents
Google DeepMind is one of the most steadfast proponents of generative world models. Its Genie series is a benchmark in this direction. The release of Genie 3 (August 2025) marked the first time an AI-generated world achieved real-time interactivity. It employs an autoregressive architecture to generate video frame by frame while receiving user action inputs. This approach enables it to learn the relationships between actions and environmental changes from unlabeled internet videos, freeing it from reliance on traditional 3D engines and physical rules.
DeepMind’s strategic intent is clear: to develop Genie into an “infinite playground” for training general intelligent agents (such as its SIMA 2 project). By training in countless virtual worlds generated by Genie, AI agents can learn highly generalized strategies to cope with the ever-changing scenarios of the real world. Genie 3 can not only simulate the physical world but also generate fantasy worlds, historical scenes, and even ecosystems, providing AI with unprecedented diverse training data. Its core capabilities include:
- Autoregressive World Modeling: Generating frame by frame, learning physics from observations rather than hardcoding.
- Long-Term Memory Consistency: Maintaining scene coherence for several minutes through emergent memory mechanisms.
- Multimodal Input Support: Generating worlds from various inputs such as text, images, photos, and sketches.
OpenAI: The Evolution of Sora and the AGI Vision
OpenAI is also exploring the path of video generation as a world simulator through its Sora series models. From Sora (2024) to Sora 2 (2025), OpenAI’s goal has consistently been to “teach AI to understand and simulate the physical world in motion.” Sora 2 has made significant progress in physical realism, multi-scene control, and audio-video synchronization. Although OpenAI has not yet clearly demonstrated its interactivity like DeepMind, it positions Sora as a foundational milestone for “achieving AGI,” implying that its ultimate goal is also to construct a dynamic world model for intelligent agents to learn and interact.
Cognitive Path: Centered on Abstract Representation and Prediction
In contrast to the generative approach’s “brutal aesthetics,” the cognitive approach argues that the key to intelligence lies not in pixel-perfect reproduction but in learning efficient, abstract representations of the world and performing predictions and planning in that abstract space. This path is championed by Turing Award winner and Meta’s chief AI scientist, Yann LeCun.
Meta AI (AMI Labs): The Non-Generative Revolution of the JEPA Architecture
Yann LeCun believes that relying solely on generative models (like LLMs and video generation models) leads to a “dead end” on the path to AGI, as they are tasked with predicting too many unpredictable details, resulting in low learning efficiency and a lack of true understanding. His proposed solution is the Joint Embedding Predictive Architecture (JEPA).
The core idea of JEPA is to perform predictions in an abstract representation space. Its workflow is as follows:
- An encoder encodes the input (like video frames x) into an abstract representation s_x.
- A predictor predicts the abstract representation s_y of a future video frame y based on s_x.
- The training objective is to make the predicted representation s_y’ as close as possible to the true representation s_y.
Since the model does not need to generate complete future images at the pixel level, it only needs to focus on important, predictable semantic information while ignoring unpredictable details like the swaying of tree leaves. This allows the model to learn more essential and robust world dynamics.
Meta has launched a series of models along this line:
- I-JEPA (2023): For images, learning powerful visual features by predicting the representations of occluded parts of images.
- V-JEPA (2024): For videos, learning the dynamic laws of the physical world by predicting the representations of occluded areas in spacetime.
- V-JEPA 2 (2025): Demonstrated that the V-JEPA model pre-trained on massive internet videos can become an actionable world model with only a small amount of robot interaction data fine-tuning, achieving advanced results in robotic manipulation tasks.
- VL-JEPA (2025): Extends JEPA to the visual-language domain, achieving more efficient and profound multimodal understanding by predicting the abstract semantic embeddings of text descriptions.
In early 2026, Yann LeCun left Meta to establish AMI Labs (Advanced Machine Intelligence Labs), aiming to elevate the JEPA architecture to new heights, constructing AI systems capable of understanding the physical world, possessing persistent memory, and reasoning and planning complex action sequences. This represents a distinctly different path to AGI compared to the generative approach.
Embodiment and Industrial Application Path: Centered on Solving Practical Problems
The third path is more pragmatic, focusing not on building a universal world simulator but directly applying the concept of world models to solve specific industrial problems, especially in autonomous driving and robotics. This path emphasizes “execution” and “implementation.”
Tesla: End-to-End AI and the “Shadow Mode”
Tesla is a typical representative of this path. Its Full Self-Driving (FSD) system has fully transitioned to an “end-to-end AI” architecture since version V12. This means that the vehicle’s driving decisions no longer rely on a set of manually written rules (like “stop at red lights”) but are mapped directly from multi-camera video inputs to driving controls (steering, throttle, brake) by a single neural network. This neural network itself is an implicit world model. It internalizes the understanding and predictive capabilities of traffic dynamics, vehicle behavior, and the physical world by learning from billions of miles of real driving data. Musk believes this “reflexive” approach based on vision and reaction is closest to biological driving. Despite its controversial “black box” nature, it represents one of the largest applications of world models in the real world.
Huawei: Pangu Model Empowering Various Industries
Huawei’s Pangu model showcases the potential of world model concepts in broader industrial applications. The Pangu model is not a single model but a family of models, with its core positioning as “solving industry problems.” In the 2025 release of Pangu 5.5, its multimodal large model includes world model capabilities, enabling the construction of digital physical spaces for intelligent driving and embodied robot training. For instance, in autonomous driving, the Pangu world model can generate subsequent multi-camera videos and LiDAR point clouds based on the first frame scene and control information, providing massive high-quality synthetic data for training end-to-end models, significantly reducing reliance on expensive real-world data collection. Additionally, Pangu has introduced physical modeling frameworks into fields like weather forecasting, mining, and steelmaking, achieving precise prediction and optimization of complex industrial processes through the construction of industry-specific “world models.”
The Evolutionary Direction of AI and Philosophical Insights
The paradigm shift from large language models to world models is not only an evolution of AI technology paths but also a profound cognitive revolution. It forces us to re-examine the essence of intelligence, the relationship between humans and machines, and even our own existence. This evolutionary process is filled with far-reaching philosophical insights, as if projecting thousands of years of philosophical speculation onto code and silicon chips.
Plato’s Cave: The Cognitive Dilemma and Path of AI
Plato’s “Allegory of the Cave” provides an excellent philosophical metaphor for understanding the evolution of AI. In this allegory, prisoners are locked in a cave for life, only able to see shadows projected on the wall by firelight, believing these shadows to be the entirety of reality. Only one prisoner is freed, walks out of the cave, and sees the real world, realizing that the shadows in the cave are merely projections of reality.
Large language models are like prisoners living in the cave. The entire world they “see” consists of massive amounts of text and image data—these data are the “shadows” cast by the real physical world after being perceived, thought, and recorded by humans. LLMs, by learning the patterns of these shadows, become the smartest prisoners in the cave, able to vividly describe, imitate, and even combine these shadows, but they have never seen the real objects that produce these shadows and cannot understand the three-dimensional structures and physical laws behind them. This is why LLMs can write beautiful poems about the sun but do not know that the sun emits light and heat; they can describe gravity but cannot predict that an apple will fall.
World models represent an attempt for AI to escape the cave. They no longer content themselves with studying the shadows on the wall but try to infer from these shadows what the real, three-dimensional world outside the cave is like and what rules it follows. The internal simulator constructed by world models is AI’s reconstruction of the “real world” in its mind. Through this model, AI can begin to understand “reality” itself, rather than just “projections of reality.”
Embodied intelligence is AI’s true escape from the cave, using its “body” to perceive sunlight and touch all things. By directly interacting with the physical world, AI obtains firsthand, undistorted sensory data, continuously validating and correcting its world model. This process is akin to the liberated prisoner in the allegory, who, upon first encountering sunlight, feels pain and confusion but ultimately gains knowledge of the truth. The evolutionary path of AI is a journey from being a “master of shadows” in the cave to becoming a “world explorer” who steps out of the cave.
The Brain in a Vat and the Ultimate Inquiry of AI
The concept of world models inevitably leads us to deeper philosophical questions, such as the “Brain in a Vat” thought experiment and the mystery of “self-awareness.”
The “Brain in a Vat” imagines a brain placed in nutrient fluid, simulating all sensory experiences through computer electrodes, making it believe it lives in a real world. In a sense, an AI agent undergoing “dream training” in a world model is akin to a “brain in a vat.” Everything it experiences is a “virtual reality” generated by its internal simulator. This raises a profound question: how do we distinguish between simulation and reality? If an AI’s world model is perfect enough that its “experiences” cannot be functionally distinguished from the real world, can we say it possesses some form of “reality”? This even prompts us to reflect on ourselves: is our perceived reality not also a product of our brain’s “biological world model”?
Ultimately, the evolution from LLMs to world models marks AI’s transition from mimicking human “outputs” (language, images) to mimicking human “processes” (perception, prediction, thinking, action). This will not only give rise to more powerful and general AI systems but also serve as a mirror reflecting the essence of human intelligence and consciousness. By constructing these “artificial minds,” we may come unprecedentedly close to the ancient philosophical question—“Know Thyself.” On this road to AGI, technology and philosophy intertwine in unprecedented ways, jointly shaping the future of humanity and intelligence.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.